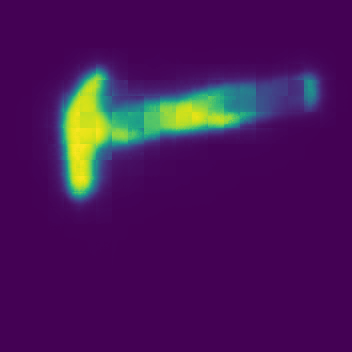
Qualitative Comparison against baselines
We compare our affordance model against two baselines using CLIP features - ClipSeg and CliPort on the RAVENS dataset. Spatula and Sauce Pan are seen at training time while Hammer is unseen for CLiPort. For our method, we annotate one exemplar from each category.
Hammer

|

|

|

|
Ground Truth |
ClipSeg |
CliPort |
Ours |
Sauce Pan

|

|

|

|
Ground Truth |
ClipSeg |
CliPort |
Ours |
Spatula

|

|

|

|
Ground Truth |
ClipSeg |
CliPort |
Ours |